Have insights to contribute to our blog? Share them with a click.

1. We Could Cut Incident Correlation Time by 45% After Replacing 11 Siloed Monitoring Tools With a Single Observability Layer, Here's the Architecture.
Most engineering teams don't have a monitoring problem. They have a fragmentation problem. Logs live in one place. Traces in another. Infrastructure metrics somewhere else. When something breaks at scale, the tools are all present but no one can read them together fast enough to matter.
The architecture we've built solves exactly this.
1.1 Here's what's inside it.
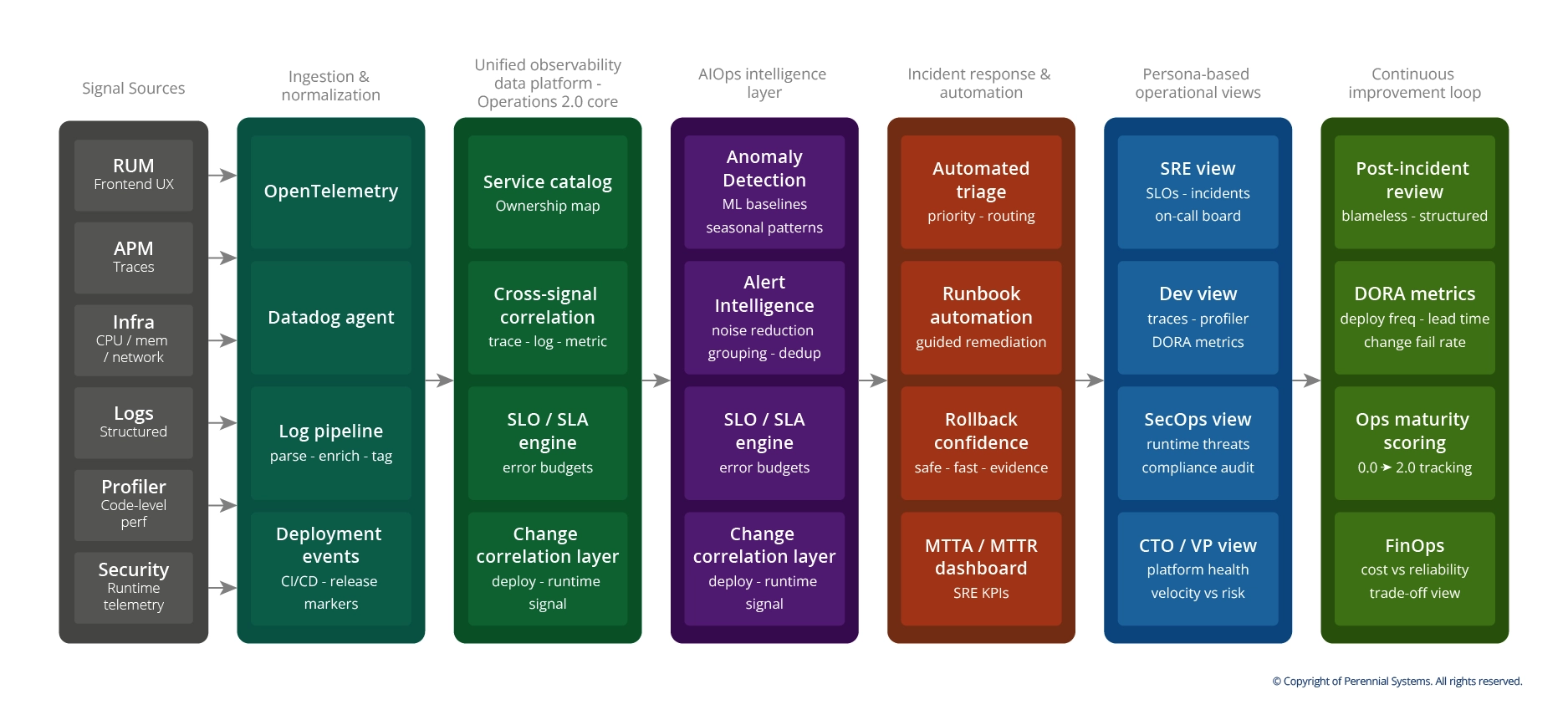
1.2 Six signal types, one ingestion pipeline
The foundation collects six telemetry streams: Real User Monitoring for frontend experience, APM traces across service dependencies, infrastructure metrics at the resource level, structured logs, continuous code-level profiling, and runtime security telemetry. Every signal enters through a normalized ingestion layer, Open Telemetry collectors feeding Datadog agents, tagged with service, environment, and release version before anything downstream touches it.
1.3 Correlation built in, not assembled during incidents
The unified data platform is where Operations 1.0 ends and 2.0 begins. A service catalog holds the full dependency map, so blast radius is quarriable in seconds, not reconstructed under pressure. Traces, logs, and metrics are linked by design. And critically, every deployment event is timestamped and correlated against runtime behavior, so when a release causes a regression, the signal-to-cause path is already drawn.
1.4 AIOps on top of clean data
With a unified signal foundation, the intelligence layer actually works. ML-based anomaly detection runs against proper baselines. Alert grouping and deduplication cuts noise before it reaches on-call engineers. Root cause suggestion surfaces probable causes alongside blast radius maps. And predictive capacity monitoring flags issues before they become incidents.
1.5 Four disciplines, one surface
The persona layer is often skipped in observability designs. We didn't. SREs see SLOs, error budgets, and on-call state. Developers see traces, profiler data, and DORA metrics. SecOps sees runtime threat signals tied to change events. Leadership sees platform health against delivery velocity, finally in the same view.
1.6 The feedback loop is the architecture
Post-incident reviews feed back into detection rules. DORA metrics surface where release velocity is introducing reliability risk. Maturity scoring tracks your progression from reactive Operations 1.0 to correlation-driven Operations 2.0, with an audit-ready evidence trail for MAS TRM Section 14 and BNM RMiT 10.1 compliance reviews.
If your team is still operating across more than five monitoring tools, you are likely carrying hidden incident response debt. We have mapped this architecture for banks across Singapore, Malaysia, and the Philippines.
Request a 30-minute BFSI Observability Maturity Assessment we will benchmark your current stack against Operations 2.0 and show you the consolidation path.
If you want to understand the layers of the AIOps maturity framework and assess where your bank stands check the
Acknowledgments
This guide was shaped through engineering insight, design thinking, and real-world observability experience.
Contributor
Shruti Sogani
Shruti contributed to the guide by ensuring the content remained insightful, well-structured, and aligned with the evolving realities of GenAI transformation.
Design & Visuals
Shriram Pathak
Shriram translated operational complexity into intuitive visuals that simplify architecture, telemetry, and correlation workflows.
Tech Partners
Ruchil Shah & Varsha Shinde
Ruchil and Varsha brought technical depth and implementation perspective, grounding the guide in scalable engineering and operational practices.
Web & Digital Experience
Javed Tamboli
Javed crafted the digital experience, ensuring the guide feels seamless, polished, and easy to navigate across platforms.


Medha Sharma
About the Author
Hey, I’m Medha - Marketing & Content Lead at Perennial Systems where I turn complex tech into stories that actually make sense (and occasionally spark a 'wait, I get it now' moment). With 5+ years of writing for Fintech, AI, and DevOps, I’ve learned one thing: good content isn’t just about clarity - it’s about connection.
I write for the curious, the technical, the skeptical, and the C-suite - because great ideas deserve to be understood, not just documented.
Off the clock? I’m probably chasing a football, chasing sunlight underwater, or curled up with a Chimamanda Ngozi Adichie novel and a giant cup of coffee.
Have insights to contribute to our blog? Share them with a click.
0 comments